Blockchains
BNB Beacon Chain
Layer de governança e staking do ecossistema da BNB Chain
Desenvolvedores
Ecossistema
Staking
Earn BNB and rewards effortlessly
Tokenization Solutions
Get Your Business Into Web3
Comunidade
opBNB: Turbocharged for the Future - 10k TPS, 200M Block Gas Limit

opBNB doubled throughput capacity to 10K TPS
In 2024, we set our sights on a bold goal: raising the opBNB block gas limit from 100M/s to 200M/s, translating to a blazing-fast 10k TPS for transfer transactions from 5k. Today, we're thrilled to announce that opBNB has reached this performance milestone by doubling the throughput capacity.
Imagine lightning-fast trading dApps, where every millisecond counts. Picture immersive blockchain games, where seamless interactions keep you in the action. opBNB is built to handle it all.
Below are the details of how we achieved this milestone.
Testing environment and achievement
Deployment - minimize the network performance computing cost
During the pressure testing, we noticed direction connection requires additional connection cost and may impact the efficiency of transaction receiving. Therefore, instead of direct connection with sequencer, we choose the p2p connection via a proxy node to minimize the computing resource waste to make sure the bottleneck is not on the network connection.
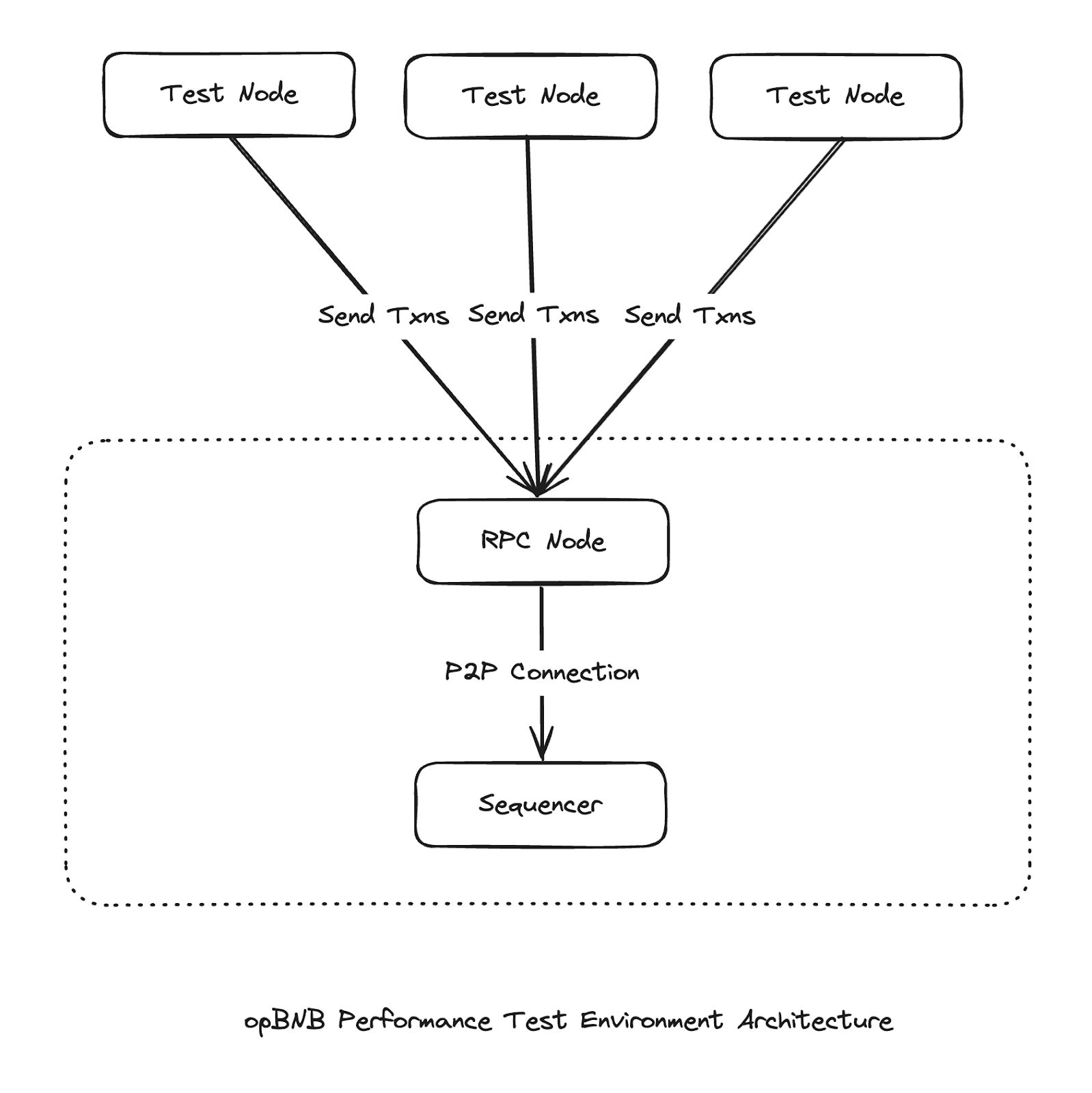
Test Chain Status - Simulate real use case of opBNB
To simulate the real mainnet data, in the test environment, we conjured up an environment with a total 12500k accounts with 10k active accounts.
Taxonomy of block production
opBNB is built with the OP Stack, and there are two clients, which are RollupDriver(op-node), and EngineAPI(op-geth). The RollupDriver is the scheduler that manages the whole mining process, to trigger the EngineAPI to include L2 transactions into a L2 block. The following diagram is a typical process of opBNB block production.

- (Kick-off)EngineDriver uses the current L2 block hash(FCS) and Payload Attributes(PA) to kick off the whole process by calling the API of engine_forkchoiceUpdated with FCS and PA as parameters.
- (Block Production)EngineAPI will initiate the block production process and return the PayLoad ID to Rollup Driver.
- (Block Production)Then Engine API will take payload by engine_newPayload function to execute, validate and commit the block candidate.
- (Finalizing)Then the Rollup Driver will call engine_forkchoiceUpdate to update the chain to include the latest block.

Optimization of Scheduling to remove the scheduling bottleneck
The current design of the scheduling has a bottleneck that can cause time waste, which will reduce the time of block production. Originally, the timer of block starts from the kick off time, and after 600ms, the productions must be disrupted to leave enough time for finalizing. Which looks like below. That means the total time for kickoff and Block production is 600ms.
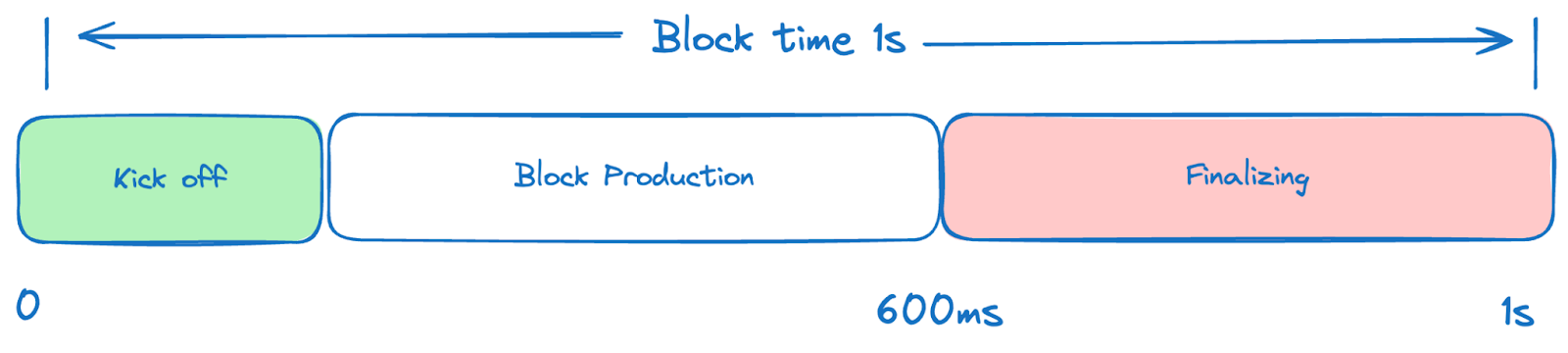
Because of the 600 ms time limit, If we want to optimize the performance, the only option we have is to reduce the time cost of kick off (retrieve the L1 state and prepare the parameters of FCS and PA). However, this is quite difficult(Although we have introduced the techniques to reduce this init process, will introduce later). At the same time, even if we can optimize the finalizing process, the 400ms has already been pre-allocated to the finalizing. If the finalizing did not need 400 ms to finalize. The sequencer then needs to be idle for a while, which is a huge waste for us.
To solve this problem, opBNB introduced schedule optimization to solve this problem by changing the schedule logic as below.

We removed the 600ms hard limit for kickoff + block production, and changed the logic of block time. The timer starts from the previous finalizing process, and there is no hard limit anymore. So in this case, we can introduce the kick off optimization and block production optimizations together to reduce the finalizing and kick off time, and block production will have more time to include transactions in next blocks.
Kickoff optimization - make L1 state retrieve 20x faster
L1 state is a must for L2 block production, and according to the protocol, each L1 block can be used to produce 600 L2 blocks, therefore we do not need to make the L1 state retrieve a synchronized step.
opBNB introduced a dedicated process to pre-fetch the L1 state(PR1, PR2), and save the L1 state in a cache for L2. By doing this, the L2 can fetch the L1 state in an asynchronous mode, and because of cache, the whole process can be reduced from 200 ms or above to less than 10ms.
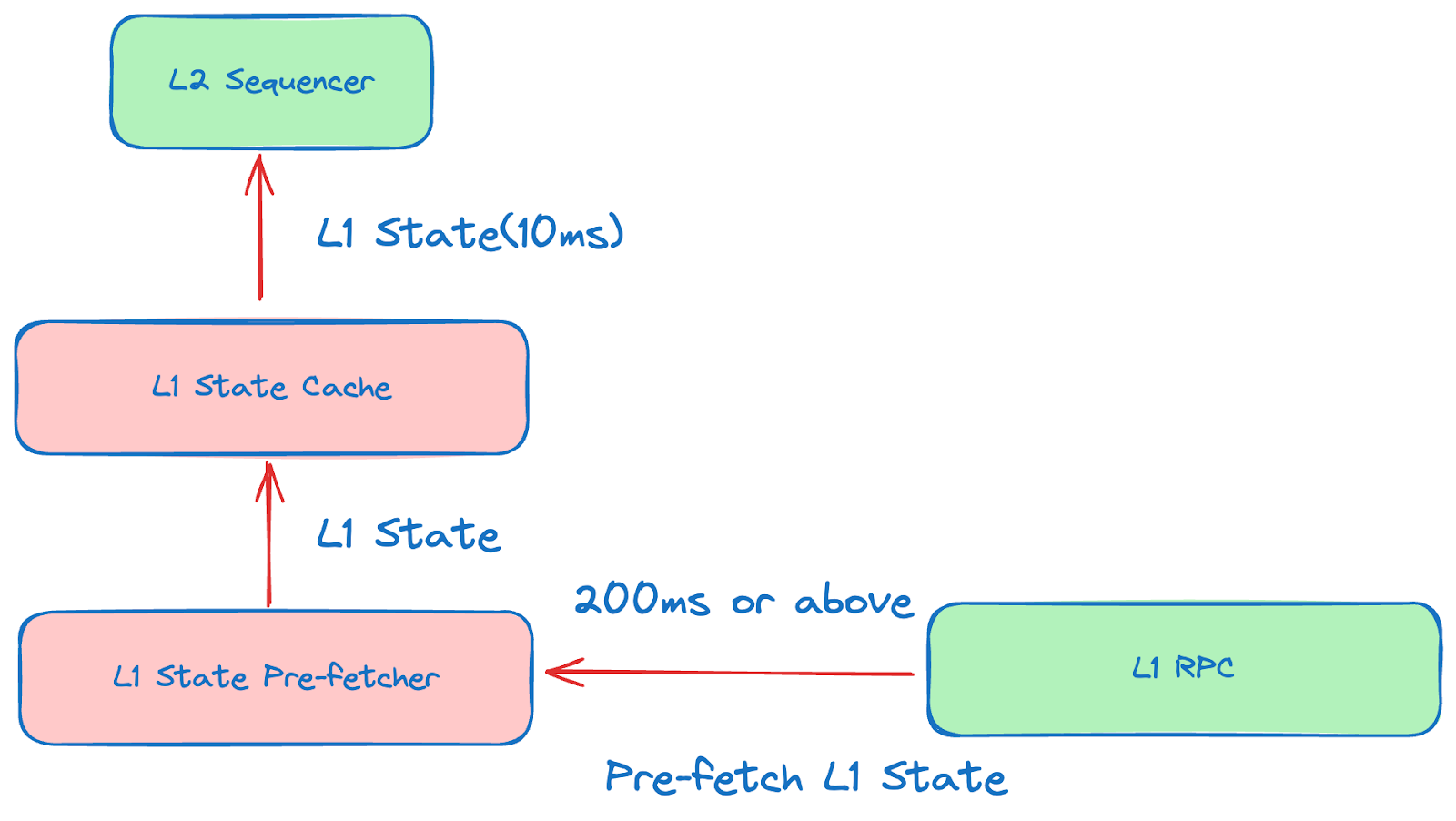
The sequencer does not need to wait for L1 endpoints to retrieve the data, it usually takes 200ms or longer, especially when there is a long latency for L1 endpoints. All L1 state retrieves can be done within 10 ms.
Block production optimization - boost block production throughput by cache and concurrency
Transaction Execution Cache
The initial block production has several steps, and transaction execution is needed during the assemble block process. The execution results, including the transaction log, receipts, and state info can be reused in the engine_newpayload process.
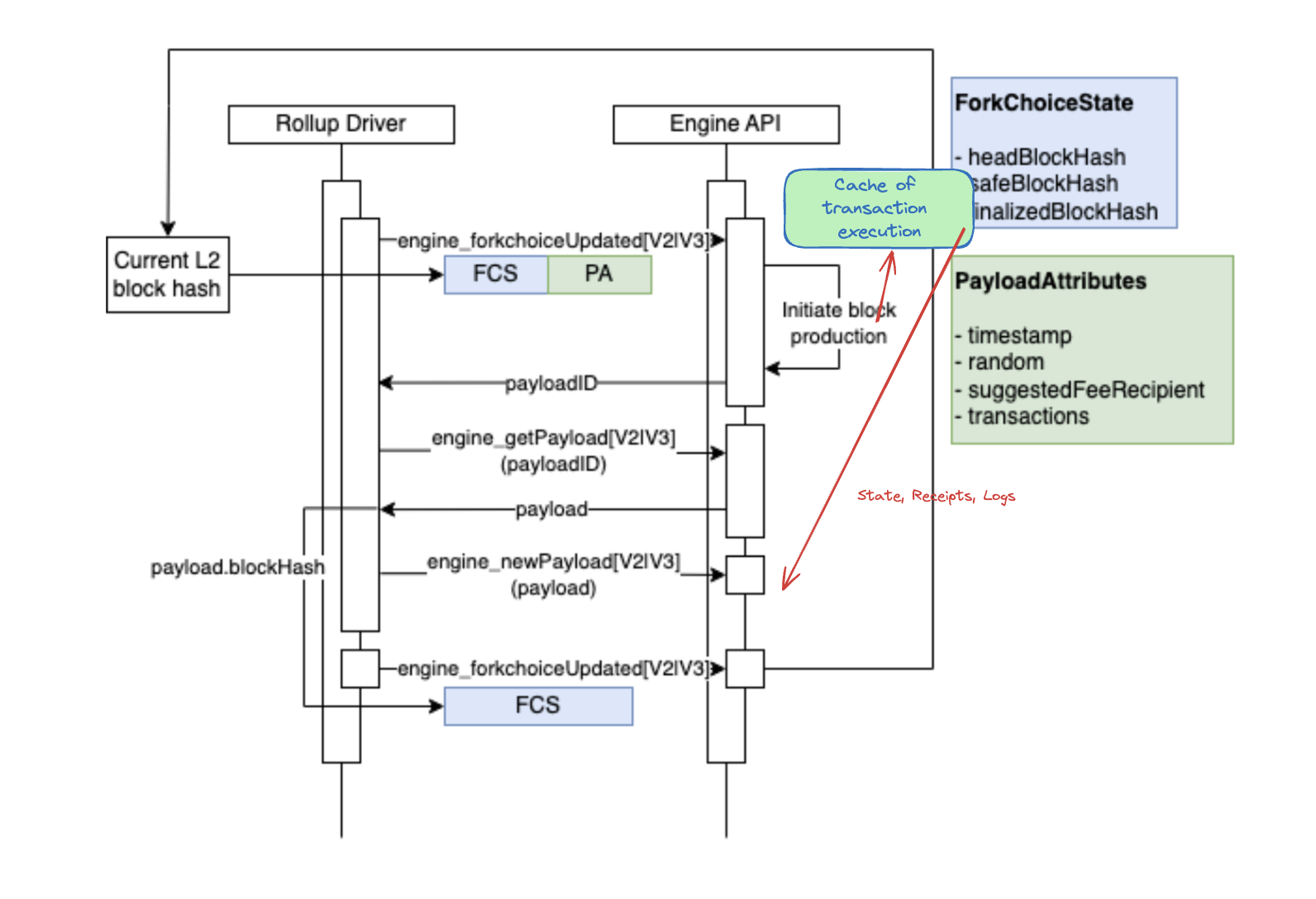
The default logic of OP Stack in the engine_newPayload has three steps, which are 1. Execution transaction of payload, 2. Validate transactions, 3. Commit. As we cached the translation execution result, it can be reused in these steps, so we can reduce the steps to validate block and commit block.

Concurrent Block Commitment
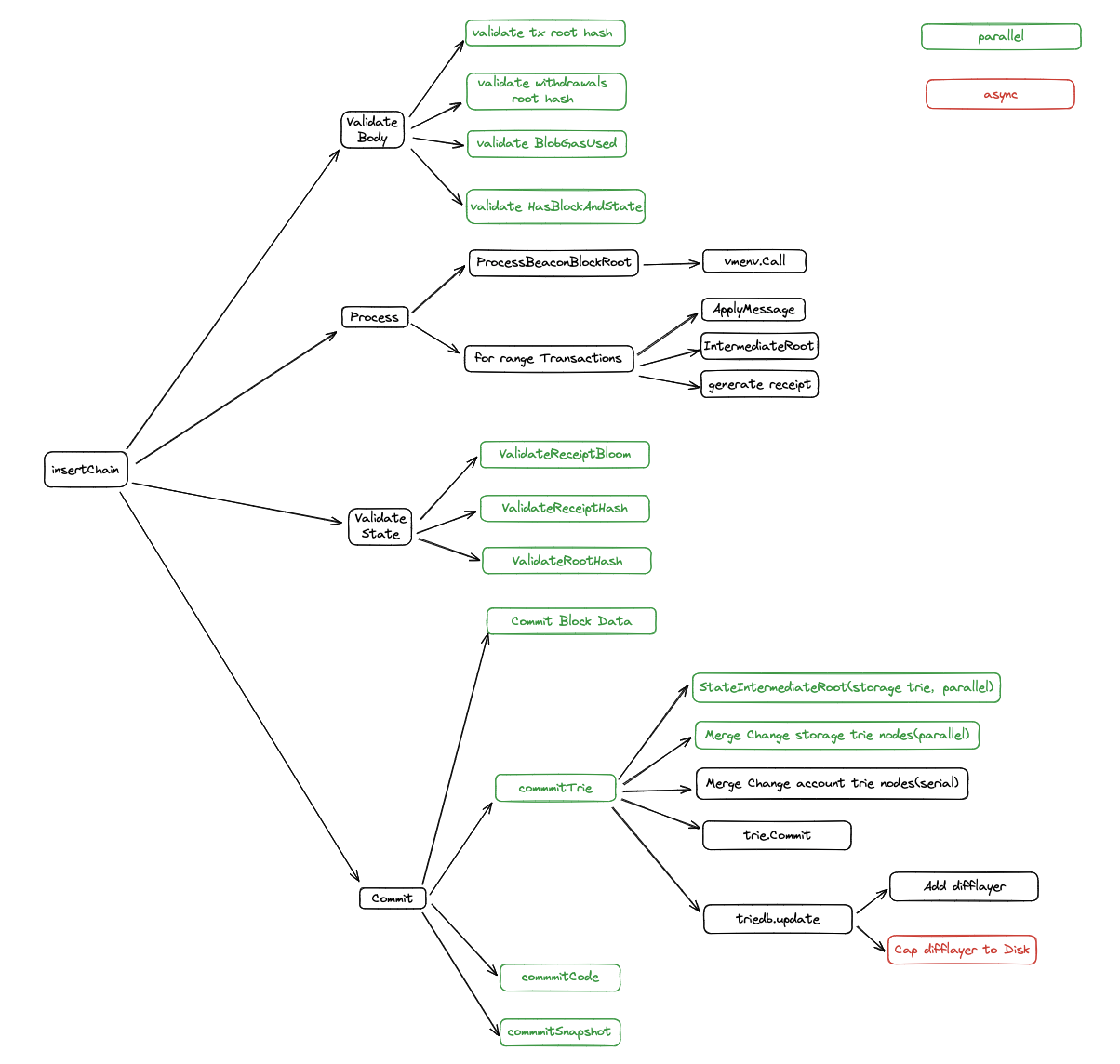
Block commitment originally was a series of steps that needed to be executed in sequence. Such as validating block body, process transactions, validate state, and commit. These steps can be separated into concurrent processes, and some of them can also be executed in an async step.
Below is the diagram to clarify the changes we introduced to optimize the verify and commitment process.
Test result
Hardware Specifications
AWS m6in 12X large + IO2 disk(IOPS 6000 throughput 1500MB/s)
opBNB tech stack version: op-geth 0.4.3, op-node 0.4.3
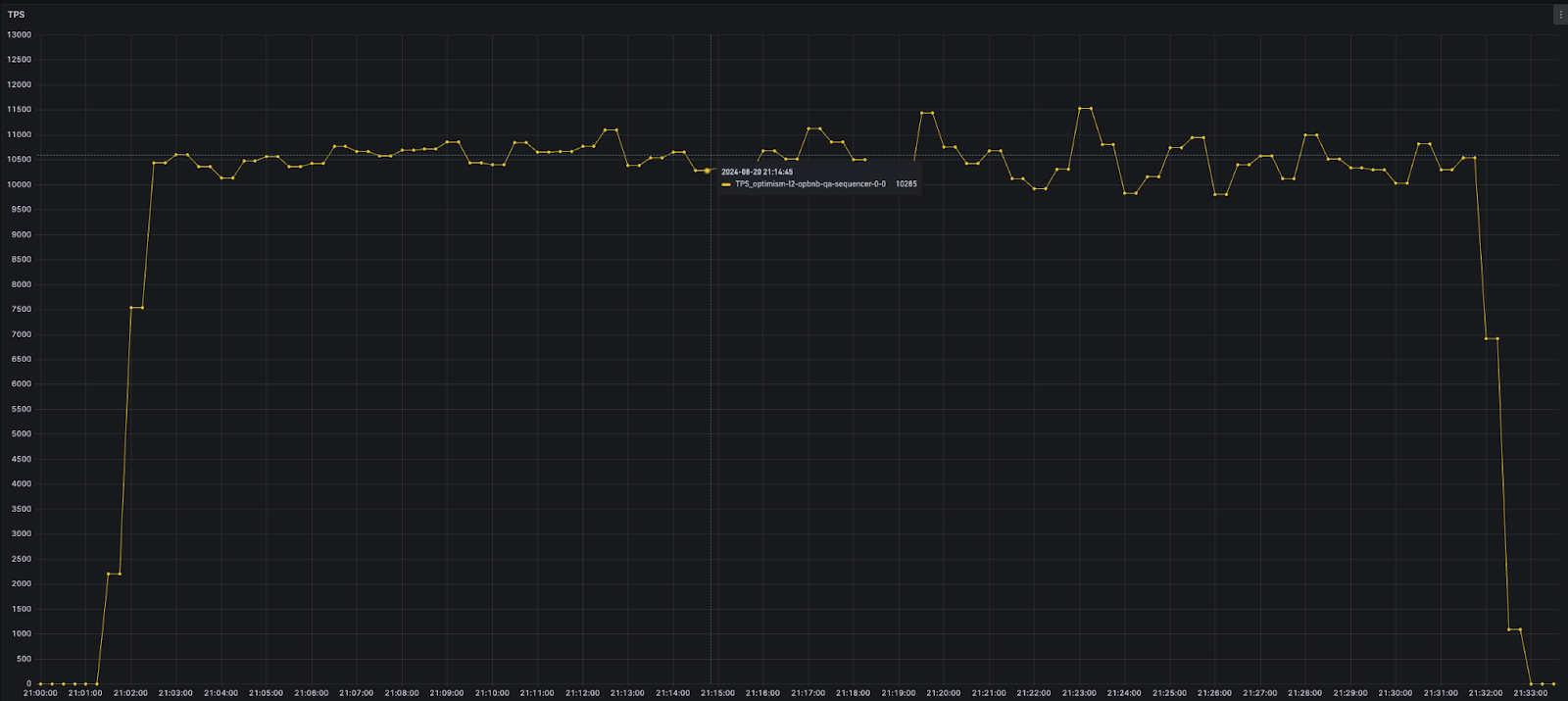
After introduction of the optimization we discussed earlier, the TPS of transfer transactions reached a range between 10500 and 11500.
In Closing
At BNB Chain, we follow the philosophy of continuous improvement and innovation. As a result of our efforts, opBNB has successfully doubled its throughput to 10,000 TPS by increasing the block gas limit from 100 M/s to 200M/s. The improvements allow for faster L1 state retrieval, streamlined transaction execution, and concurrent block commitment, resulting in a high-performance environment suitable for demanding applications like trading dApps and blockchain games.
Follow us to stay updated on everything BNB Chain
Website | Twitter | Telegram | Instagram | Facebook | dApp Store | YouTube | Discord | LinkedIn | Build N' Build Forum